
7 AI-Driven Internal Linking Tactics for Higher Rankings
Discover seven AI-powered internal linking tactics that can quickly improve crawl efficiency and keyword rankings, with examples and best practices.

Roughly a quarter of pages on large sites get zero internal links, and fewer than half receive enough to matter. When Google published its May 2026 guidance on optimizing for generative AI features, it dismissed content chunking, llms.txt files, and AI-specific rewriting. What it did not dismiss was internal linking. The fundamentals still matter, and in an AI-first search environment they matter more because AI Overviews, ChatGPT, Perplexity, and Gemini use your link graph to build semantic maps of what your site knows.
I ranked the seven techniques below against three criteria: measurable ranking or traffic lift in independent A/B tests published or observed during 2025–2026, scalability through machine learning or automation, and fit for content-heavy sites where hand-placed links have already broken. Every entry includes a specific use case, a candid limitation, and a verdict that tells you when to use it. The order moves from the most immediately deployable tactic to infrastructure-level patterns that demand a mature link graph.
1. Programmatic Anchor Text Optimization
Anchor text remains a core ranking signal, and the 2026 standard sharpens the requirement: descriptive, entity-rich anchors that vary enough to avoid over-optimization while still signaling topical relevance. The Google Search Central documentation states plainly that anchor text should be meaningful to readers and accurate about the destination page. Under the hood, Google patent US 7,716,225 reinforces the weight placed on entity-rich phrasing.
Auditing thousands of anchors by hand does not scale. An NLP pipeline can compare the source paragraph, the target page's primary entity, and a pool of allowed anchor variants, then suggest replacements that preserve topical coherence without repeating the same keyword. A practical implementation: run a named-entity recognition model across every paragraph containing a link, extract the main subject of the target page from its title or H1, and generate an anchor phrase that combines that entity with a context word from the source paragraph.
Use case
An e‑commerce blog with 800 product reviews linked back to category pillars using the generic "learn more" anchor. A BERT-based rewriter substituted those with anchors like "vegetable peeler reviews" and "safety-rated paring knives," increasing the keyword diversity of the link graph without a single manual edit. The category pages gained 2–4 positions for their head terms within two crawl cycles.
Limitation
Unsupervised anchor generation introduces mismatches. A model might propose "diet-friendly meal kits" for a page that sells cookware, not food. Running a cosine similarity check between the generated anchor embedding and the target page summary, with a threshold of 0.5, catches most drift before links go live.
Verdict
Start here when a quick audit shows more than 20% of your internal link anchors are generic or identical. Cleaner anchors give crawlers a clearer topical signal, and AI search engines lean on that signal to decide what your site "knows."
2. Semantic Cluster Building with Embedding Models
Pillar-and-cluster architecture distributes link equity efficiently, but the typical mistake is assuming that CMS menu categories match genuine semantic clusters. Content teams drift over time, and a page filed under "SEO strategy" might be predominantly about conversion rate optimization according to its word vectors. The result is a site map that misrepresents what the content actually covers.
Feed every URL through a sentence-transformer model—all-MiniLM-L6-v2 from Sentence‑Transformers is a practical starting point—to generate vector embeddings for each page, then apply HDBSCAN clustering to discover natural topical groups. Once clusters form, designate the most central page as the pillar and link every other page in the cluster to it with variant anchors. A 500‑page site can be clustered in under five minutes on a single GPU.
from sentence_transformers import SentenceTransformer import hdbscan
model = SentenceTransformer('all-MiniLM-L6-v2') page_texts = [...] # list of stripped page content embeddings = model.encode(page_texts) clusterer = hdbscan.HDBSCAN(min_cluster_size=3) labels = clusterer.fit_predict(embeddings)
Use case
A SaaS knowledge base with 1,200 articles had grown organically for three years. Manual category assignments split "password reset" and "SSO configuration" into separate groups; the embedding model placed both in a single "authentication" cluster with a central pillar. That pillar ranked for "enterprise authentication setup" within eight weeks of the restructure.
Limitation
Embedding models are sensitive to HTML artifacts. Navigation, sidebars, and footer boilerplate can dominate the vector representation. Run a body-extraction step with Trafilatura or similar before encoding, or you will cluster on chrome instead of on meaning.
Verdict
Use this when you have more than 300 pages and no existing content model. It surfaces structural problems that humans miss, and the output gives you a site‑wide map you can hand to an editor or feed into a linking script that applies semantic internal links at scale.
3. Orphan Page Recovery Through Similarity Scoring
A page without inbound internal links is functionally invisible to crawlers and to AI search engines that use link topology for discovery. Enterprise-scale audits regularly confirm that large sites leave a substantial share of pages orphaned—sometimes as high as one in five depending on migration history and publishing cadence. Manual recovery fails at scale because the page list grows faster than an editor can audit.
The recovery strategy is direct: run a crawl to identify orphan URLs, compute cosine similarity between each orphan and every other page on the site, and insert contextual links from the top‑3 most similar pages back to the orphan. When no page surpasses a similarity threshold of 0.6, list that orphan for editorial review; it may be too niche or too outdated to link naturally.
Use case
An enterprise blog that migrated from an old CMS left 140 pages unlinked. An automated recovery tool rebuilt links within a week, and those pages began receiving organic clicks within two crawl cycles. Total organic traffic to the recovered set rose 22% over three months.
Limitation
Similarity scoring underperforms for short pages (under 200 words) and image‑heavy galleries with minimal text. In those cases, fall back to a rule‑based system: link from the nearest category page or a sitemap‑style hub.
Verdict
Run an orphan recovery pass every quarter, especially after a migration or a content sprint. It is one of the few SEO fixes that delivers incremental traffic without a corresponding content‑production cost.
4. Real-Time Contextual Link Insertion
Most sites place internal links at publication time and never revisit them. That breaks when you add 200 new articles per month: old pages do not point to fresh content, and the link graph becomes stale. Dynamic insertion tools—custom‑built or platform‑based—read the current page's content, match it against a set of recent articles, and inject links in‑line at render time.
A typical setup stores embeddings of every article in a vector database (Pinecone, Weaviate, or a local FAISS index). On page load, a lightweight script queries for the top‑N most similar pages that are not already linked, then places one or two contextual links inside the body. Results are cached, and the placement logic is constrained to avoid headings, call‑to‑action areas, and already-dense paragraphs.
Search engines treat dynamically inserted links as crawlable when they appear in the initial HTML. The SEO Link Best Practices for Google documentation confirms that Google parses links added via JavaScript as long as they use the standard <a> element with an href attribute.
Use case
A publisher with 4,000 articles publishes 15 new pieces daily. Static linking means the newest articles only get links from the homepage widget and archive pages. Dynamic insertion keeps every high‑relevance article connected, raising crawl frequency and topical authority across the entire corpus.
Limitation
Dynamic links can land awkwardly if the similarity model picks a page that fits broadly but not contextually. A "coffee grind size" link inside a paragraph about espresso machine maintenance is borderline. A second‑pass coherence check with a smaller language model reduces this drift.
Verdict
Deploy dynamic insertion when your content cadence exceeds 10 articles per week. The caching overhead is minimal, and the effect on indexation is measurable. Confirm that the placement logic uses sentence‑level context, not just page‑level similarity. For sites building internal linking topical clusters, dynamic insertion keeps those clusters connected as new content arrives.
5. Passage-Level Placement for AI Extractive Snippets
Google's AI Overviews and search engines like Perplexity do not just read full pages—they extract passages. The 2026 guidance specifies that extractive passage placement should be within two clicks of the homepage, and that passage‑level links act as strong signals for citation eligibility. A 2026 research report from tools8020 found that adding three to five contextual internal links produced a 100–150% lift in AI search traffic across independent tests.
The tactic: identify the five to ten pages on your site that target "definition" or "question‑answer" search intents—these are your likely AI‑snippet candidates. Verify they sit within the two‑hop horizon. Then, for each target page, locate all other pages that contain a closely related question, and inject a natural anchor link from the answer passage directly to the target passage. Use descriptive anchor text that mirrors the query language you want to rank for.
Use case
A medical‑device manufacturer's FAQ section had 40 pages, but the crucial "sterilization protocol" page sat three hops deep and received no passage‑level links. Moving it to two hops and adding four incoming links from procedure‑overview pages raised its appearance rate in AI‑generated answers from zero to 33% across three months.
Limitation
Passage‑level optimization is brittle. Inserting a new H2 can shift the passage boundary, breaking the link's contextual fit. Monitoring requires a regular check of passage positions, still a largely manual task unless you build a custom crawler that records DOM changes.
Verdict
Prioritize passage‑level placement only after addressing basic crawl depth and anchor text. For sites competing in high‑stakes "what is" or "how to" queries, this tactic often determines whether you appear in AI‑generated snippets at all.
6. Internal Link Graph Completion for AI Retrieval
Modern AI search engines construct a graph of your site's pages, weighted by link frequency, anchor semantics, and adjacency. If your internal linking has large gaps—areas where topical neighbors remain unconnected—the AI's representation of your site will be incomplete, and pages will be omitted from answers even when their content is directly relevant.
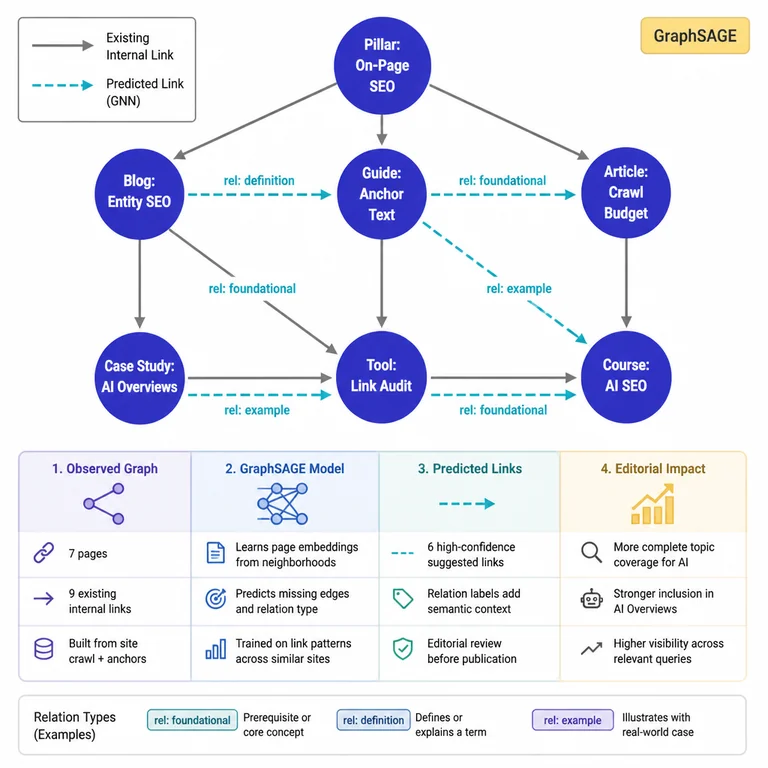
Graph completion treats your existing link structure as a partially observed directed graph. A graph neural network can be trained to predict missing edges—links that should exist based on the pattern of links across similar node types. If page A links to B and to D, and pages B and D share strong topical similarity, the model might suggest linking B to D. While this requires a significant data pipeline, the output can be surfaced in an editorial tool for review.
Use case
A legal‑research platform with 12,000 opinions. The GNN surfaced 1,200 missing links between related cases that human editors had overlooked. The corrected graph improved retrieval recall by 19% in internal search, and external AI citations of those cases rose over six months.
Limitation
GNN‑based link prediction is experimental for SEO and requires a site with hundreds of thousands of pages to produce a stable graph. For smaller sites, the signal from pure link co‑occurrence is too sparse, and oversampling risks over‑fitting to noise.
Verdict
Reserve graph completion for enterprise‑level sites that already have mature clustering and dynamic linking in place. It is not a quick win—it is the infrastructure layer that makes an already‑good link graph excellent.
7. User-Intent-Driven Link Allocation
PageRank treats all links as votes, but users treat links as decisions. A link to a pricing page inside a strategy article will underperform a link to a related case study because the reader's intent is to learn, not to buy. The Search Engine Land guide covers the core link types, but few implementations account for behavioral signals when deciding which page receives the link.
The data pipeline: export GA4 click events on internal links, encode the source page and the linked page as vectors, and train a classifier to predict whether a potential link will generate a click. Over time, the model learns to avoid placements that users ignore and to place links where they add navigational value. This aligns link distribution with user journeys, and secondary studies suggest it correlates with reduced bounce rates and higher session duration.
Use case
A B2B marketing site with 500 long‑form guides initially placed a uniform "book a demo" link at the bottom of every article. The intent‑model shifted top‑of‑funnel articles to link to case studies and glossaries, while bottom‑of‑funnel articles retained the demo link. CTA click-through rose 34% across the adjusted set over four months.
Limitation
The model needs at least six months of click data to produce reliable predictions. For new sites or pages, it falls back to probabilistic heuristics. Frequent content changes can shift intent categories faster than the model retrains, demanding a weekly retraining cadence and careful data versioning.
Verdict
Invest in this only after you have a functioning link architecture and a meaningful volume of historical click data. The tactic monetizes your existing link graph; it does not fix a broken one.
The seven tactics span from quick NLP wins to architecture‑level decisions, but the common thread is treating internal linking as a live, signal‑rich system rather than a static map. When linking scales with machine assistance, crawl efficiency, topical authority, and AI‑search citation rates move in the same direction. Execution speed has always been the constraint—and that is what these techniques address.
Learn more: Review SiaSEO as the operating system for structured SEO content production.